-
RAFT: Adapting Language Model to Domain Specific RAG연구/논문리뷰 2025. 12. 15. 01:38
1. RAFT의 등장 배경
대형 언어모델은 일반적인 상식, 요약, 추론에서는 강력한 성능을 보이지만, 실제 도메인 문서 기반의 질문에 대해 안정적으로 답변하는 데에는 한계가 존재한다. 특히 RAG(Retrieval-Augmented Generation) 시스템에서는 검색된 문서가 정답을 포함하지 않거나, 정답과 유사해 보이지만 실제로 무관한 문서가 함께 반환되는 경우가 흔하다.
이런 상황에서는 모델이 오답을 생성하거나 불안정한 답변을 내놓기 쉽다.

RAFT 는 이 문제를 모델 차원에서 해결하기 위해 고안된 방법이다. 질문과 함께 관련 문서와 비관련 문서가 섞인 문서 집합을 제공하고, 모델이 정답 근거 문서를 구분해 답변을 생성하도록 학습하는 방식이다.
RAFT의 핵심은 검색 기반 QA 환경(open-book setting)을 모델 학습 단계에서 직접 시뮬레이션한다는 점에 있다.
2. RAFT 논문에서 제안하는 문제 설정
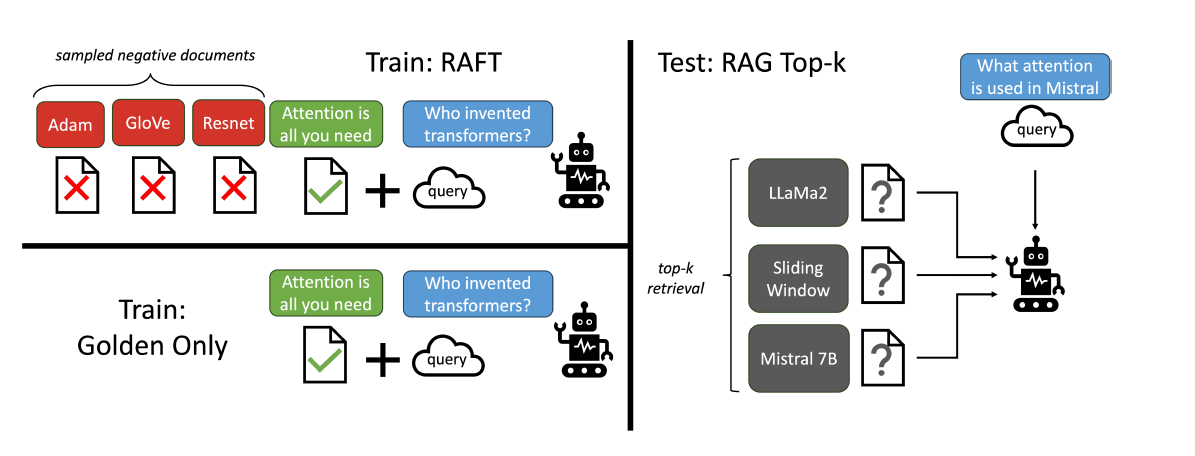
RAFT 논문은 LLM을 “도메인 특화 open-book 시험” 상황에 적응시키는 문제로 정의한다.
이 설정에서 모델은 질문(Q)과 함께 여러 개의 문서(D)를 입력받고, 문서에 포함된 정보를 근거로 답변(A)을 생성해야 한다.논문에서는 문서를 다음 두 가지로 구분한다.
- Golden document (D*)
질문에 대한 정답을 도출할 수 있는 근거 문서
하나일 수도 있고, HotpotQA처럼 여러 개일 수도 있다. - Distractor documents (Di)
질문과 함께 제공되지만, 정답 근거를 포함하지 않는 문서
RAFT의 학습 데이터는 다음과 같은 형태로 구성된다.
- P%의 데이터
Q + D* + D1 + … + Dk → A* - (1−P)%의 데이터
Q + D1 + … + Dk → A*
즉, 일부 학습 샘플에서는 의도적으로 golden document를 제외한 채 학습을 진행한다.
논문에서는 이것이 모델이 문서를 무조건 신뢰하지 않고, 주어진 문맥을 해석하는 능력을 기르는 데 도움이 된다고 설명한다.이 과정은 SFT 방식으로 수행되며, 답변 A*에는 Chain-of-Thought 형태의 reasoning과 문서 인용(citation)이 포함된다.
논문에서는 이러한 reasoning 생성이 모델 성능과 학습 안정성에 중요한 역할을 한다고 나타냈다.3. RAFT가 기존 SFT+RAG 방식과 다른 점
RAFT는 다음 두 접근의 한계를 동시에 지적한다.
- 기존 RAG(in-context learning)
문서를 참고하지만, 도메인이 고정되어 있음에도 “학습” 기회를 활용하지 못함
→ open-book 시험을 공부하지 않고 보는 것에 비유 - 기존 도메인 SFT
답변 스타일과 도메인 지식은 학습하지만, 테스트 시 문서를 어떻게 읽고 활용해야 하는지는 학습하지 않음
RAFT는 이 둘의 중간 지점에 위치한다.
모델은 fine-tuning 단계에서 문서를 직접 참조하면서 답변을 생성하도록 학습되며, 동시에 distractor 문서가 존재하는 불완전한 문맥 환경에도 노출된다.논문의 표현을 빌리면, RAFT는 “open-book 시험을 대비해 실제 시험 환경을 가정하고 공부하는 방식”에 가깝다.
4. 논문을 읽고 느낀점
RAFT 논문에서는 문서를 golden / distractor 두 범주로만 구분한다.
이 구분은 이론적으로는 충분하지만, 실제 검색 환경을 떠올리면 한 가지 아쉬움이 남는다.실제 RAG 시스템에서는 distractor 문서가 항상 “완전히 무관”하지 않다.
- 어떤 문서는 질문 주제와 매우 유사하지만 정답은 포함하지 않거나
- 일부 단서만 포함해 모델이 쉽게 오답을 선택하게 만들기도 한다
논문에서도 distractor의 개수와 비율(P%)이 성능에 미치는 영향을 실험하지만, distractor의 성격 차이 자체는 명시적으로 다루지 않는다. 또한, 실제 RAG 결과에서는 distractor의 개수도 항상 일정하지 않다.
이 지점이 RAFT를 실제 시스템에 적용할 때 추가적인 고민이 필요하다고 느낀 부분이다.
다만, 이러한 한계에도 불구하고 RAFT의 핵심 아이디어를 응용하면 RAG 환경에서 문서를 보다 효과적으로 활용하는 LLM을 만드는 것은 충분히 가능하다고 판단했다.
이에 따라 이후에는 RAG를 위한 파인튜닝용 학습 데이터셋을 구성하는 과정에서 RAFT 논문을 포함해 참고한 다른 연구들과,
최종적으로 어떤 형태의 학습 데이터셋을 설계했는지를 순차적으로 소개하고자 한다.
[references]
https://arxiv.org/abs/2403.10131
RAFT: Adapting Language Model to Domain Specific RAG
Pretraining Large Language Models (LLMs) on large corpora of textual data is now a standard paradigm. When using these LLMs for many downstream applications, it is common to additionally bake in new knowledge (e.g., time-critical news, or private domain kn
arxiv.org
https://github.com/ShishirPatil/gorilla
GitHub - ShishirPatil/gorilla: Gorilla: Training and Evaluating LLMs for Function Calls (Tool Calls)
Gorilla: Training and Evaluating LLMs for Function Calls (Tool Calls) - ShishirPatil/gorilla
github.com
'연구 > 논문리뷰' 카테고리의 다른 글
- Golden document (D*)