-
Efficient Reinforcement Learning via Large Language Model-based Search연구/논문리뷰 2024. 12. 14. 16:06
2024년 9월 3일 화요일 리뷰
- 개인 연구를 위해 논문을 리뷰한 내용입니다:)
(*10월달에 논문제목이 변경되어서 submission되었네요.)
https://arxiv.org/abs/2405.15194
Extracting Heuristics from Large Language Models for Reward Shaping in Reinforcement Learning
Reinforcement Learning (RL) suffers from sample inefficiency in sparse reward domains, and the problem is further pronounced in case of stochastic transitions. To improve the sample efficiency, reward shaping is a well-studied approach to introduce intrins
arxiv.org
⚠️문제점
강화학습은 생소한 도메인에서 학습 과정 중 샘플 비효율성으로 인해 고통을 받고 있다. 이를 위해 보상함수를 도입하여 RL 에이전트가 최적의 정책으로 더 빨리 수렴하도록 하는것은 매우 좋은 접근 방식이었다.
그러나 유용한 보상함수를 설계하는 것은 매우 어려운일.(도메인마다 특징이있고 전문성이 있기때문에)
- 샘플 비효율성이란?
- 강화학습은 훈련을 위한 데이터를 수집하려면 에이전트와 환경 사이에 수많은 상호작용이 필요하다는 것을 의미 하는것이다.
- => 비효율적이라는 의미
- 본 논문은 이러한 상호작용을 덜하게 해준다는것을 의미한다.
🌟Potential-based Reward Shaping
- PBRS는 강화 학습에서 정책 불변성(property invariance)을 보장하면서, 내재적 보상(intrinsic rewards)을 추가할 수 있게 해준다. 이는 기존 보상 함수에 추가적인 보상 함수를 더해주는 방식으로 작동한다.
- 수학적으로, 기존 보상 함수 𝑅에 보상 함수 𝐹를 더한 새로운 보상 함수 𝑅′=𝑅+𝐹 를 정의한다.
- 이 𝐹(내재적 보상)를 만드는데 LLM이 쓰인다는 의미로 보임 -> LLM을 통해 goal에 적합한 trajetory를 얻어서 이를 가지고 내재적 보상을 shaping해서 buffer에 업데이트 시킨다는 것.
- 우리가 흔히 알고있는 강화학습의 보상함수는 외재적 보상함수다.
🌟MEDIC 프레임워크
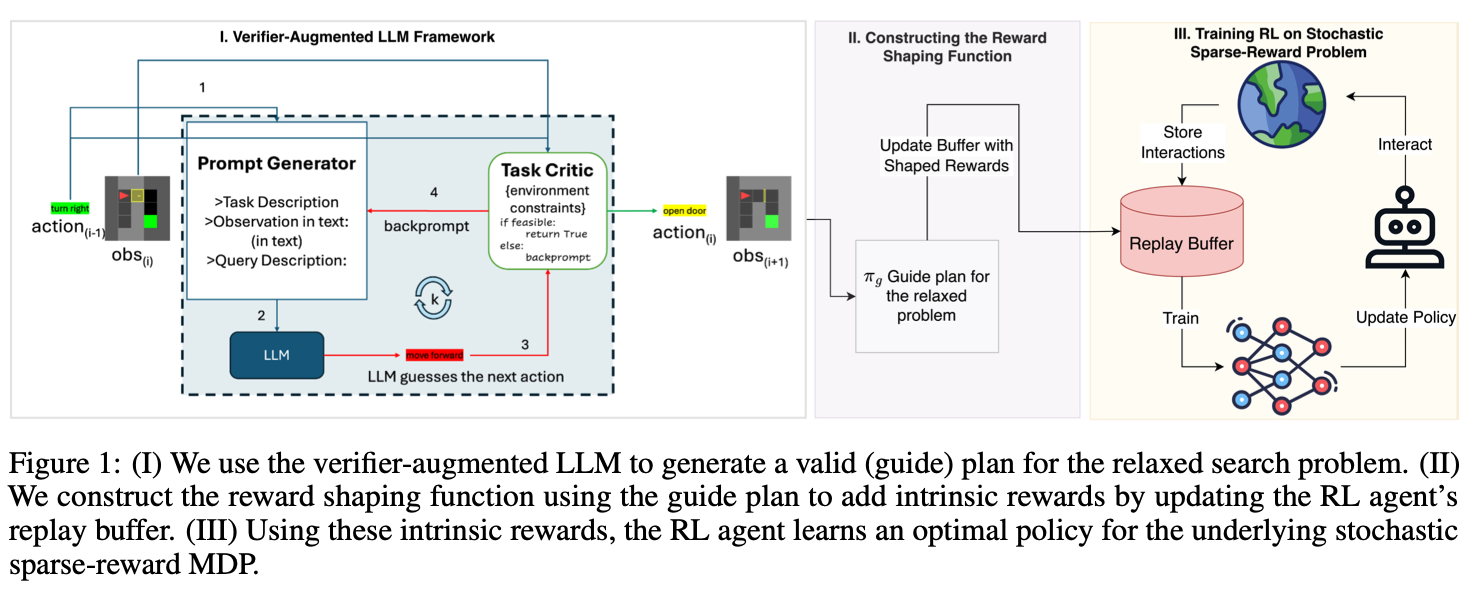
- 샘플 효율성을 위해 RL 에이전트의 리플레이 버퍼에 LLM을 통해 미리 데이터를 만들어서 넣어주는것
- 오프라인 RL 에이전트
- 모델기반 강화학습 – 환경(environment)이 모델로 들어감 / 본 논문에선 BabyAI
'연구 > 논문리뷰' 카테고리의 다른 글
- 샘플 비효율성이란?