-
iLLM-TSC: Integration reinforcement learning and large language model for traffic signal control policy improvement연구/논문리뷰 2024. 12. 14. 15:34
2024년 8월 13일 화요일 리뷰
- 개인 연구를 위해 논문을 리뷰한 내용입니다:)
https://arxiv.org/abs/2407.06025
iLLM-TSC: Integration reinforcement learning and large language model for traffic signal control policy improvement
Urban congestion remains a critical challenge, with traffic signal control (TSC) emerging as a potent solution. TSC is often modeled as a Markov Decision Process problem and then solved using reinforcement learning (RL), which has proven effective. However
arxiv.org
📝요약
- RL-based TSC system often overlooks imperfect observations caused by degraded communication, such as packet loss, delays, and noise, as well as rare real-life events not included in the reward function, such as unconsidered emergency vehicles.
- To address these limitations, we introduce a novel integration framework that combines a large language model (LLM) with RL.
- This framework is designed to manage overlooked elements in the reward function and gaps in state information, thereby enhancing the policies of RL agents.
🌟iLLM-TSC 프레임 워크
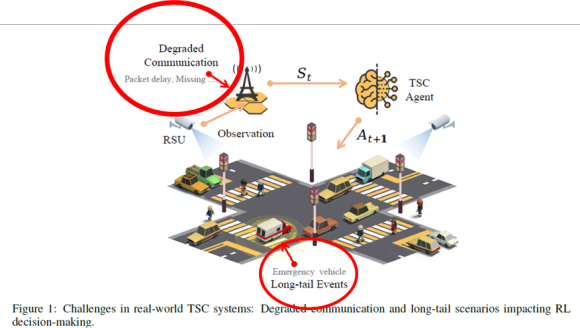
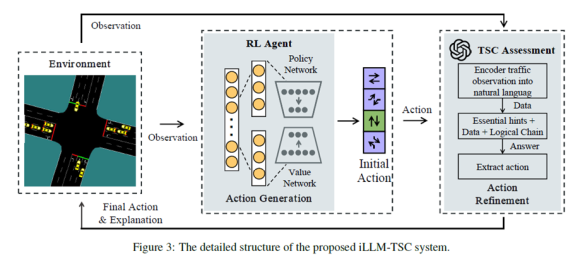
- 1단계 RL , 2단계 LLM 으로 구성되는 하이브리드 프레임워크
- 간단히 말하면 RL 에이전트의 action을 LLM을 통해 평가하고 타당하지 않을 경우 LLM이 타당한 action을 도출해 RL 에이전트에게 전달한다. 그리고 RL 에이전트는 이를 수행한다.
🌟LLM 프롬프트 구성

🌟RL Agent Design – PPO algorithm
MDP
1.State
-움직이는 차량들의 평균 속도, (움직이는 차량들이 없으면 -1)
-차량들의 점유한 도로 길이/ 총 차선 길이 (한 슬롯(t)당 평균을 낸 것)
-교통 체증 총 길이
-교통 체증 차량 수
-현재 phase
-현재 관측 시점에서 movement가 가능한지 아닌지 나타내는 이진값
-각 state값에 통신으로 인한 품질 저하가 반영된다.
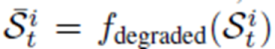
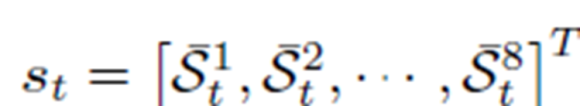
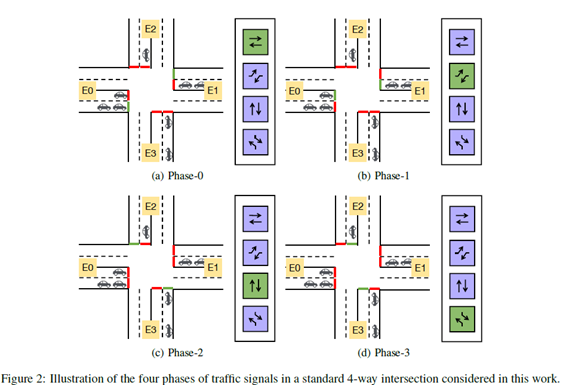
2.Action
- 4개의 phase
3.Reward
- 본 논문은 차량의 대기시간을 최소화 하는 것이 목적이고 보상함수에서는 차량의 평균 대기시간을 줄이도록 설계했다.
decision making으로써 LLM이 사용된 점이 흥미로웠다. 그러나 RL모델의 알고리즘으로 왜 PPO를 썼을까 하는 의문이... 그냥 요즘 PPO아니면 SAC여서 그런건지...다른 논문들에도 왜 해당 알고리즘을 선택했는지에 대한 이유는 명시하지 않고있다.
PPO는 병렬학습을 이용하기때문에 상당히 복잡한 환경에서 사용되어야지 의미가 있을것같은데.. 본 논문의 환경에 PPO가 적합했나? 하는 생각이 든다.
'연구 > 논문리뷰' 카테고리의 다른 글